
1、我们的目标是获取微博某博主的全部图片、视频
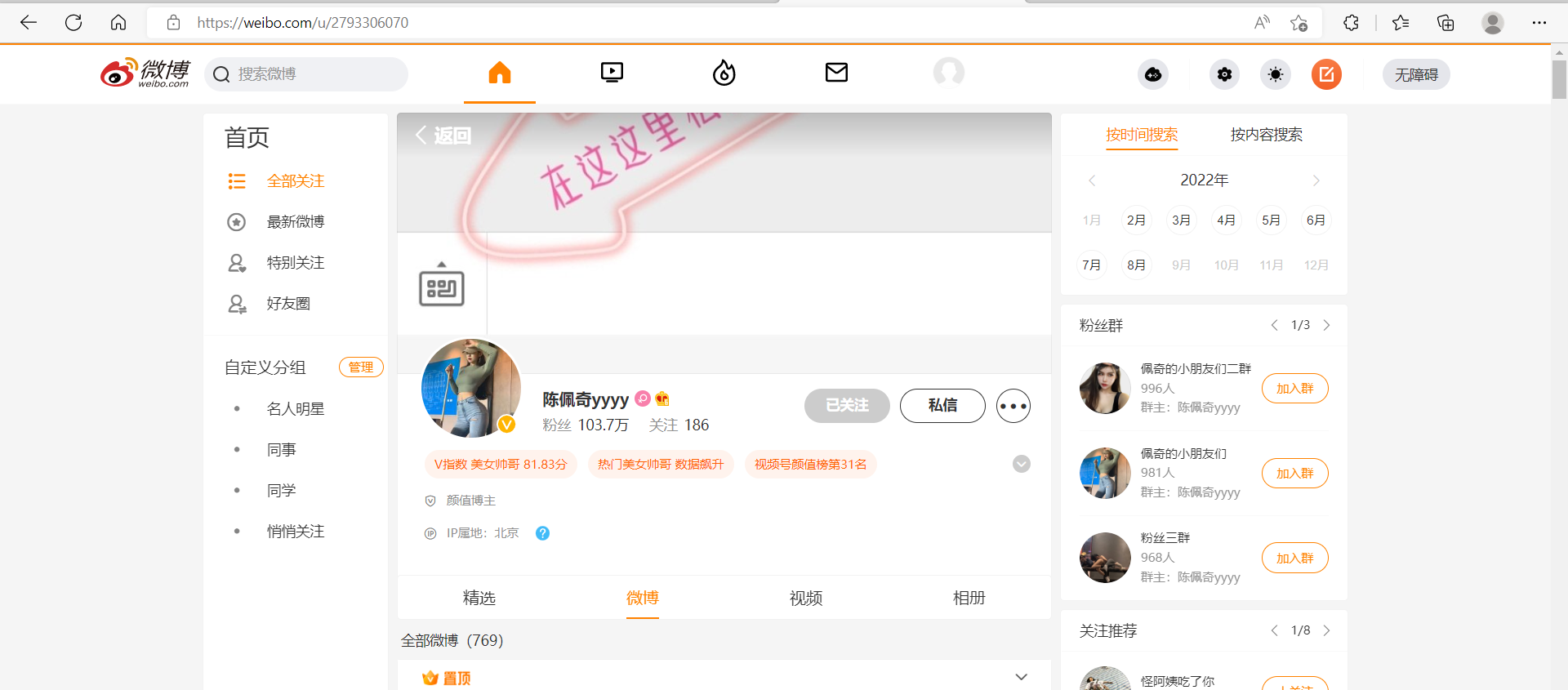
2、拿到网址后 我们先观察 打开F12 随着下滑我们发现加载出来了一个叫mymblog的东西,展开响应发现需要的东西就在里面
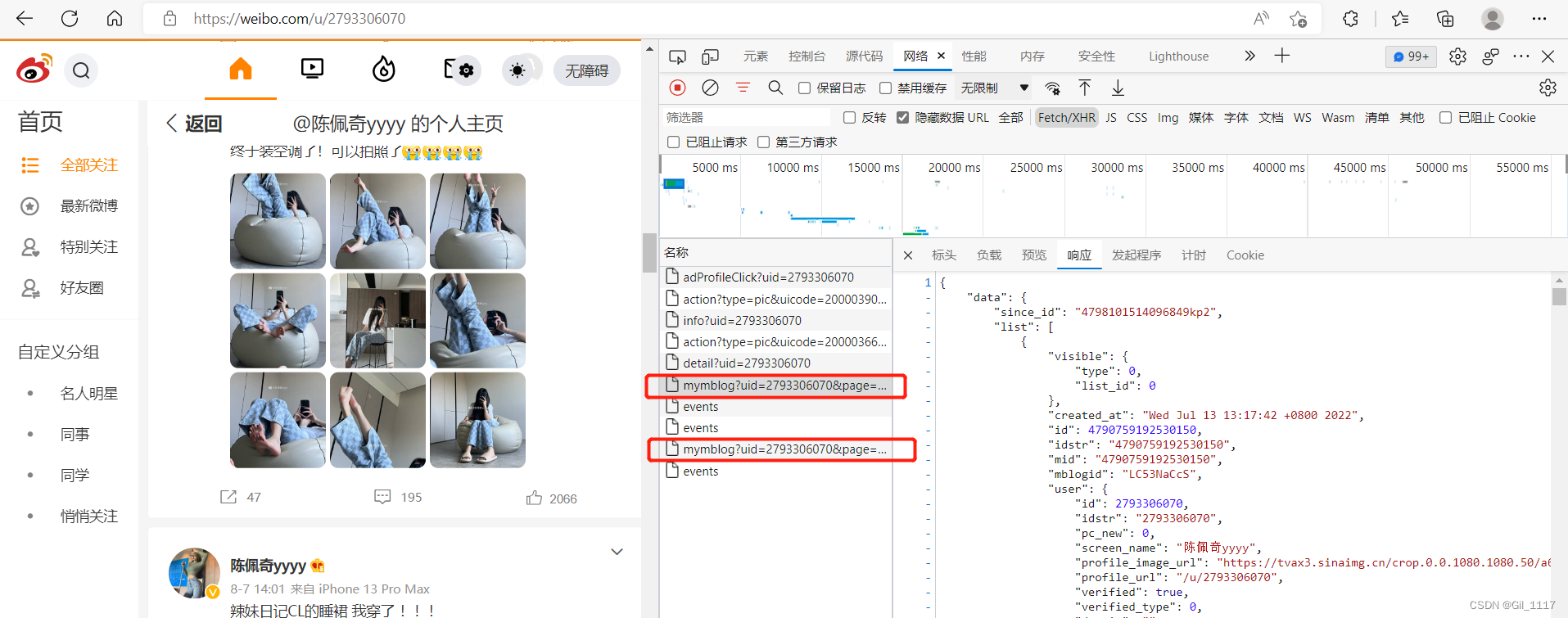
3、重点来了!!!

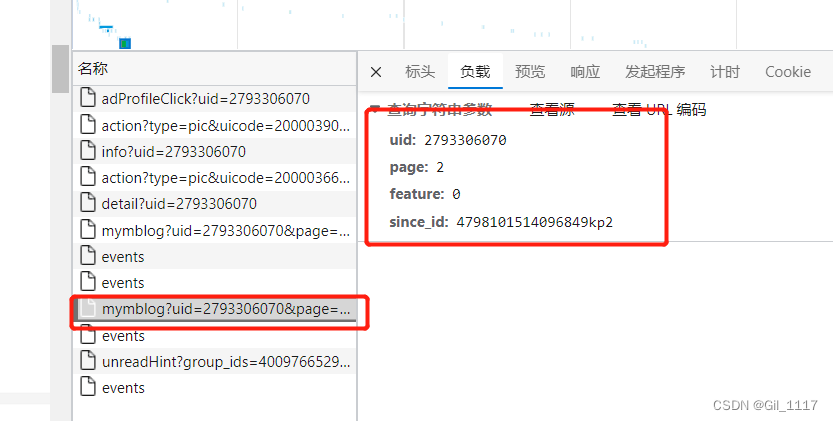
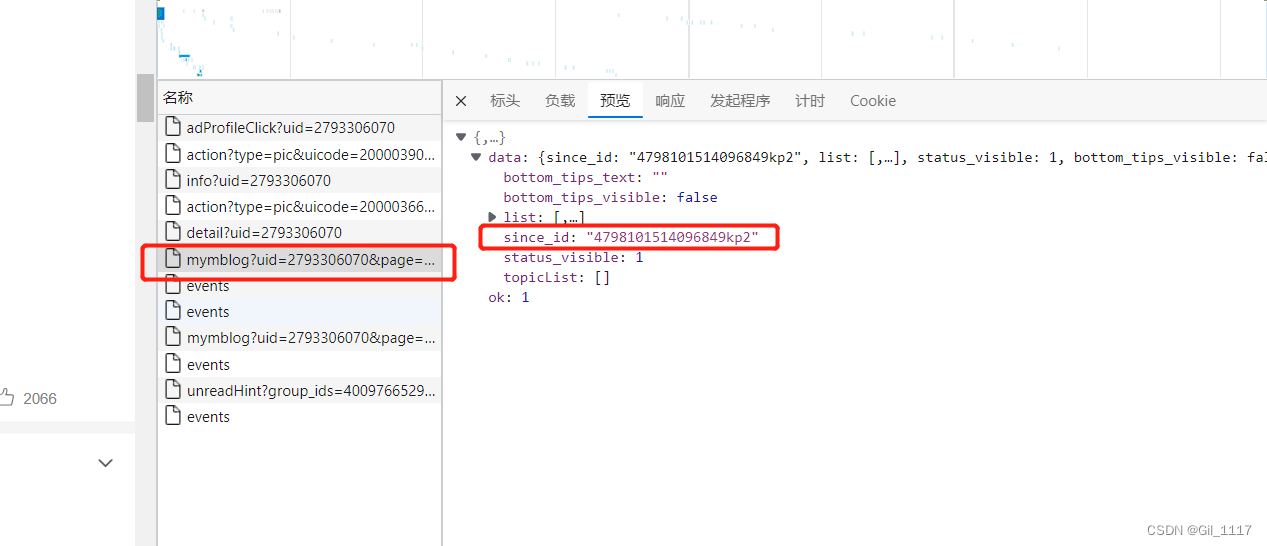
通过观察发现第二页比第一页多了参数since_id 而第二页的since_id参数刚好在上一页中能获取到,往下翻页同理 第二页带着第三页需要的参数
4、因为是get请求 接下来就是设置params对下面网址进行请求然后提取bloghttps://weibo.com/ajax/statuses/mymblog
5、不会翻页的我还发现了个简单的方法 不用带since_id参数,只需要给page来个循环也可实现循环 具体如下:
5.1、把网址设置成这样,
https://weibo.com/ajax/statuses/mymblog?uid=2793306070&page=2&feature=0&since_id=
5.2、去掉params 具体为啥不带参数也能出来 我也不清楚 反正是发现这么设置url可以实现翻页
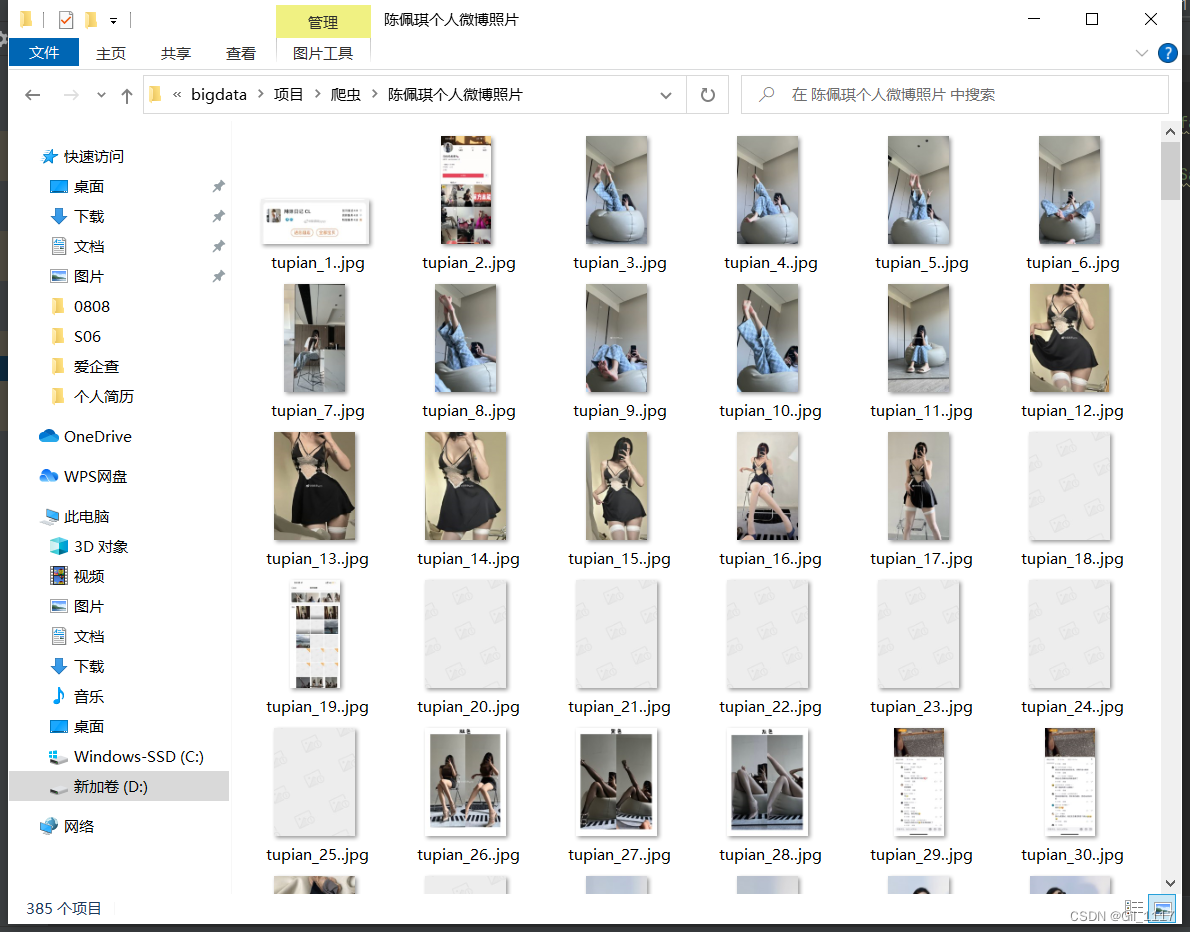
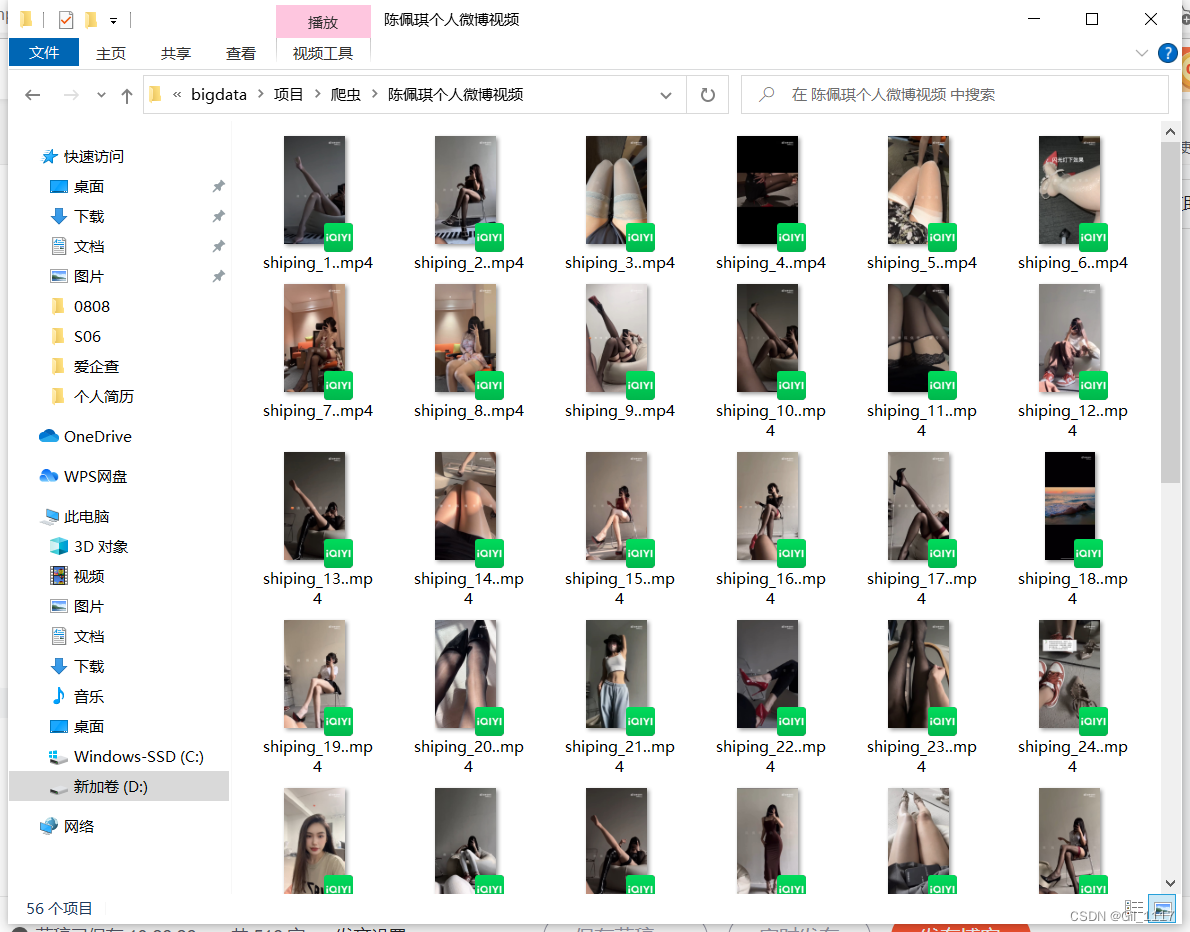
6、最后看看出来结果(部分照片属于会员可见,但是依然可以拿到高清原图。未显示出来的是因为0擦边严重被微博封了)
7、具体代码如下
1 import requests 2 3 headres = { 4 '你的': '微博cookie', 5 'referer': 'https://weibo.com/u/2793306070', 6 '你的': 'UA', 7 'x-requested-with': 'XMLHttpRequest', 8 'x-xsrf-token': '1_g5J4kMvprJh8xD1YgaHWmv' 9 } 10 11 shipindizhi = './陈佩琪个人微博视频/' 12 tupiandizhi = './陈佩琪个人微博照片/' 13 n = 1 14 x = 1 15 for g in range(1, 11): 16 url = f'https://weibo.com/ajax/statuses/mymblog?uid=2793306070&page={g}&feature=0&since_id=' 17 18 rsp_fanye = requests.get(url=url, headers=headres).json() 19 since_id = rsp_fanye['data']['since_id'] 20 print(since_id) 21 neirong = rsp_fanye['data']['list'] 22 # 获得图片(获得文本,有图片获得图片) 23 for i in neirong: 24 text = i['text_raw'].replace('\n','') 25 if 'pic_infos' in i: 26 tupian = i['pic_infos'] 27 # print(tupian) 28 for j in tupian: 29 # print(j) 30 tupian_url = i['pic_infos'][j]['mw2000'].get('url') 31 # print(tupian_url) 32 pinjie = tupiandizhi + 'tupian_%s' % x + '.' + '.jpg' 33 f = open(pinjie, mode='wb') 34 f.write(requests.get(url=tupian_url).content) 35 x += 1 36 print(pinjie+'图片保存成功!!!') 37 38 # 获得视频 39 for j in neirong: 40 if 'page_info' in j: 41 shiping = j['page_info'] 42 if 'media_info' in shiping: 43 media_info = shiping['media_info']['mp4_720p_mp4'] 44 # print(media_info) 45 pinjie = shipindizhi + 'shiping_%s' % n + '.' + '.mp4' 46 f = open(pinjie, mode='wb') 47 f.write(requests.get(url=media_info).content) 48 n += 1 49 print(pinjie+'图片保存成功!!!')
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
